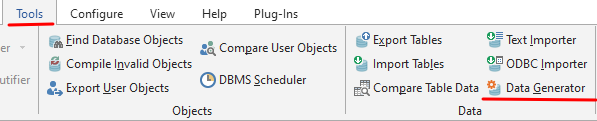
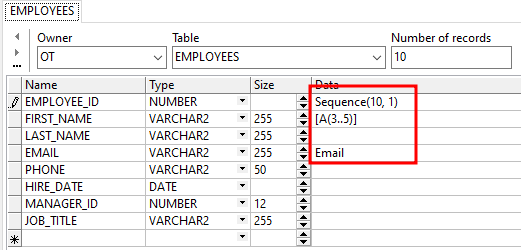
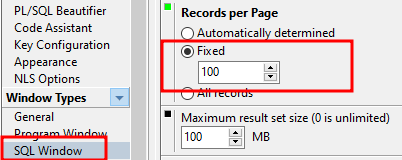
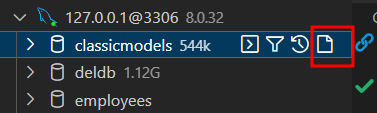
Amazon DynamoDB는 완전관리형 NoSQL 데이터베이스 서비스로서 원활한 확장성과 함께 빠르고 예측 가능한 성능을 제공합니다. DynamoDB는 분산 데이터베이스를 운영하고 크기 조정하는 데 따른 관리 부담을 줄여서 하드웨어 프로비저닝, 설정 및 구성, 복제, 소프트웨어 패치 또는 클러스터 크기 조정에 대해 걱정할 필요가 없게 합니다.
또한 DynamoDB는 유휴 시 암호화를 제공하여 중요한 데이터 보호와 관련된 운영 부담 및 복잡성을 제거합니다.
DynamoDB를 통해 원하는 양의 데이터를 저장 및 검색하고 어느 수준의 요청 트래픽도 처리할 수 있는 데이터베이스 테이블을 생성할 수 있습니다. 다운타임 또는 성능 저하 없이 테이블의 처리 능력을 확장 또는 축소할 수 있습니다.
DynamoDB는 만료된 항목을 테이블에서 자동으로 삭제할 수 있으므로 스토리지 사용량과 더 이상 관련 없는 데이터를 저장하는 비용을 줄일 수 있습니다.
from PyQt6.QtWidgets import QApplication, QWidget
# 명령줄 인수에 액세스하는 데 필요
import sys
from PyQt6.QtWidgets import QApplication, QWidget
# Only needed for access to command line arguments
import sys
# You need one (and only one) QApplication instance per application.
# 애플리케이션당 하나의 QApplication 인스턴스가 필요합니다.
# Pass in sys.argv to allow command line arguments for your app.
# 앱에 대한 명령줄 인수를 허용하려면 sys.argv를 전달합니다.
# If you know you won't use command line arguments QApplication([]) works too.
# 명령줄 인수를 사용하지 않는다는 것을 안다면 QApplication([])도 작동합니다.
app = QApplication(sys.argv)
# 창이 될 Qt 위젯을 만듭니다.
window = QWidget()
# 중요!!!!!! Windows는 기본적으로 숨겨져 있습니다.
window.show()
# Start the event loop.
app.exec()
서버 설정에서 RDS DB(Aurora) 인스턴스에 연결을 유지하고 캐시되는 커넥션 풀이 있습니다.
람다에는 세션이 없고 연결이 캐시되지 않습니다.
Why RDS Proxy?
Lambda 함수는 마이크로 VM에서 실행됩니다. Lambda는 호출 간에 마이크로 VM을 재사용합니다. 이러한 이유로 핸들러 외부(init 코드에서) 데이터베이스에 대한 연결을 생성하고 열어 두는 것이 좋습니다. 마이크로 VM이 완전히 격리되어 있으므로 서버에서와 같이 연결 풀을 사용할 수 없습니다. 이러한 이유로 우리는 RDS 프록시를 만들었습니다 . RDS 프록시는 데이터베이스에 대한 연결 풀을 유지합니다. Lambda 함수는 데이터베이스에 직접 연결하는 대신 프록시에 연결합니다.
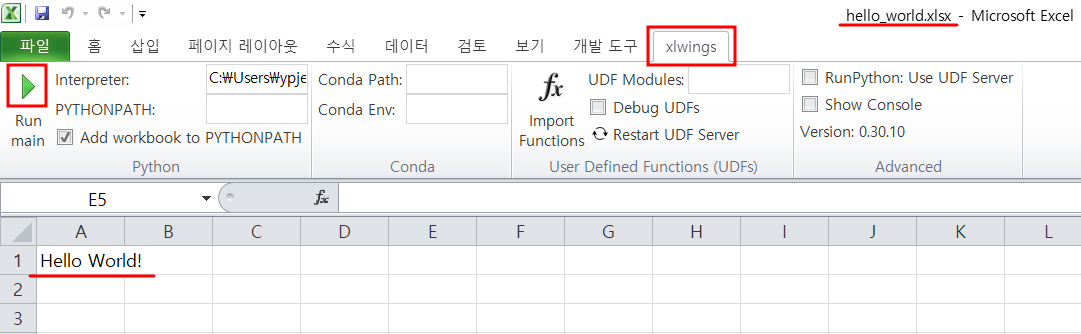
엑셀파일에서 xlwings 메뉴의 [Run main] 버튼을 클릭합니다. 아래와 같이 A1 Cell에 Hello World! 문자가 입력됩니다.
모듈 이름과 관계없이 Python 함수를 호출하려면 RunPython을 사용합니다.
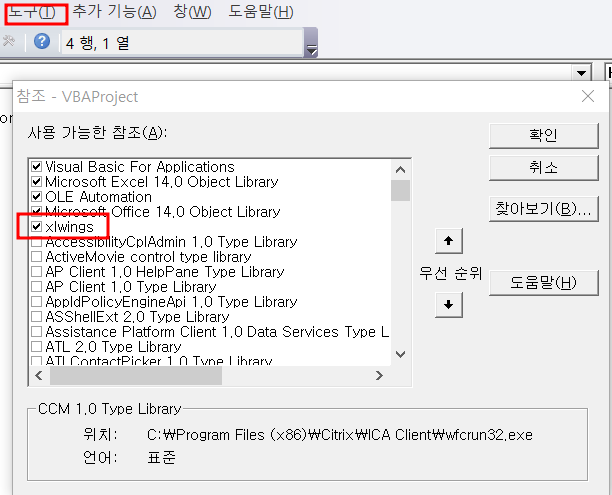
엑셀의 VBA에 [도구] - [참조] 버튼을 클릭하고 xlwings를 참조하도록 선택합니다.
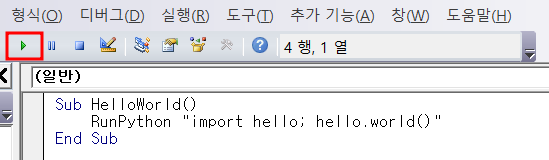
RunPython 함수를 사용한 VBA 스크립트 입니다. hello.xlsm 파일을 만들고 아래처럼 VBA 스크립트를 작성합니다.
Sub HelloWorld()
RunPython "import hello; hello.world()"
End Sub
기본적으로 "RunPython"은 Excel 과 파이썬 파일이 동일한 디렉터리에 같은 이름을 가졌다고 가정하지만, 파일 이름과 디렉토리 위치를 다르게 지정할 수 있습니다. Python 파일이 다른 폴더에 있는 경우 PYTHONPATH에 해당 폴더를 추가합니다. 파일 이름이 다른 경우 RunPython 명령어에 파일 이름을 지정합니다.
xlwings.Book.caller()를 사용하여 Excel Workbook을 호출하는 예제입니다.
6단계: 접속할 DB의 정보를 입력합니다. 본 문서에서는 Local 컴퓨터에 MySQL 서버가 설치되어 있어 localhost(127.0.0.1)를 입력했습니다.
호스트: localhost(127.0.0.1) 또는 접속하고자 하는 서버의 IP Address 또는 endpoint
사용자: db user
비밀번호: 비밀번호
포트번호 : 3306
7단계: " + Connect" 버튼을 클릭하여 DB에 접속합니다.
8단계: 촤측 데이터베이스 메뉴에 localhost(127.0.0.1) 연결이 추가된 것을 볼 수 있습니다.
9단계: 터미널을 이용하려고 아래 그림과 같이 "Open Terminal"을 클릭하면 "Free account not support open terminal!" 이라는 메시지가 출력된다. Free 버전에서는 지원이 안되고 년간 20$를 지불하는 Premium은 지원된다. 20$를 지불하면서까지 사용하고 싶은 생각은 없다.
-> 2023.09.26 현재 기준 Terminal 기능이 무료로 지원된다. "Open Termial" 을 클릭하면 아래와 같은 MySQL DB command line 화면이 보여진다.
10단계: MySQL의 각 스키마를 클릭한 후 아래 화면의 "Open "을 클릭하여 SQL 편집기를 연다.
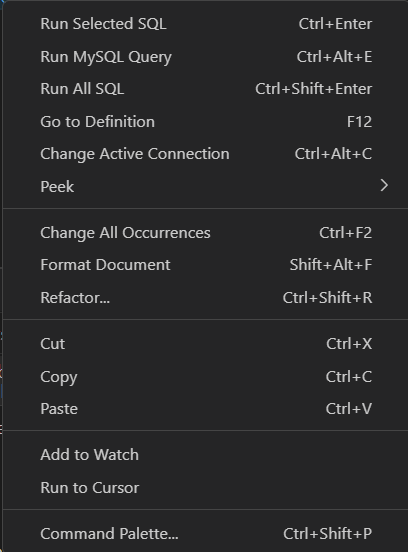
11단계: SQL 편집기에 원하는 SQL을 입력하고 "Execute" 버튼을 클릭하거나 "Ctlr + Enter"를 친다. 입력한 SQL 문장에 마우스 오른쪽을 클릭하면 SQL 실행을 할 수 있는 여러 메뉴들이 뜬다.
[마우스 오른쪽 클릭 시 사용할 수 있는 메뉴들]
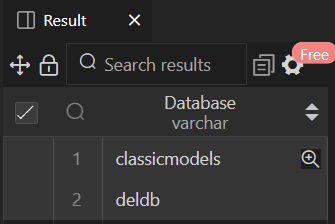
12단계: 이 MySQL 쿼리를 실행하면 아래창에 결과가 출력된다.
이러한 방식으로 VSCode를 통해 데이터베이스에 액세스하고 쿼리를 실행할 수 있습니다. VSCode로 개발 시 간단하게 DB를 조회하는 정도로 활용할 수 있을 정도이다.