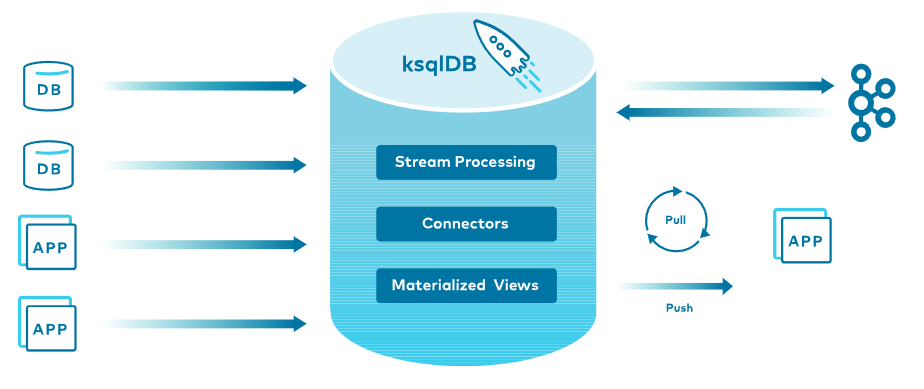
구체화된 뷰
모든 데이터베이스에서 테이블의 주요 목적 중 하나는 데이터에 대한 효율적인 쿼리를 가능하게 하는 것입니다.
ksqlDB는 Key-Value 모델을 사용하여 Apache Kafka®에 이벤트를 변경 불가능하게 저장합니다.
이 모델에서 쿼리를 좀 더 효율적으로 활용할 수 있도록 하는 것이 구체화된 뷰(Materialized Views)입니다.
Oracle 또는 MS SQLServer DBMS에서 제공하는 Materialized Views 와 유사합니다.
스트림/테이블 이중성
스트림과 테이블은 밀접하게 관련되어 있습니다. 스트림은 테이블을 파생시키는 일련의 이벤트입니다.
예를 들어, 대출 신청자의 신용 점수는 시간이 지남에 따라 변경될 수 있습니다. 변경된 일련의 신용 점수는 스트림입니다. 이 데이터는 신청자의 현재 신용 점수를 설명하는 데이터로 활용할 수 있습니다.
현재 신용 점수를 나타내는 데이터는 신용 점수 변경 데이터의 결과입니다.
기존 데이터베이스에는 redo log, bin-log, transaction log 등이 있지만 변경사항을 따로 저장하지 않는 경우 변경 사항을 조회하는 것은 쉽지 않습니다. 리두 로그는 Kafka 변경 로그보다 보존 기간이 짧을 수 있습니다. 압축된 Kafka 변경 로그는 데이터베이스 스냅샷과 동일합니다. 쿼리로 변경 사항만 조회할 수 있습니다.
구체화된 뷰
구체화된 뷰 의 이점은 전체 테이블 데이터를 조회하는 대신 변경 사항의 최종 결과만 조회할 수 있습니다.
집계 함수를 적용할 수 있습니다. 새 이벤트 생성되면 구체화된 뷰는 집계 기능으로 최종 집계 데이터를 만듭니다. 이런 식으로 새 이벤트가 도착할 때 구체화된 뷰는 "전체를 다시 계산"하지 않고 새로운 이벤트만을 계산합니다.
즉, 구체화된 뷰를 쿼리하면 효율적으로 집계된 데이터를 조회할 수 있습니다.
ksqlDB에서 테이블은 구체화된 뷰로 구현되지 않을 수 있습니다. Kafka 토픽에 바로 테이블을 생성하면 구체화되지 않습니다. 구체화되지 않은 테이블은 매우 비효율적입니다. 반면에 테이블이 다른 컬렉션에서 파생된 경우 ksqlDB는 결과를 구체화하고 이에 대해 쿼리를 만들 수 있습니다.
ksqlDB는 각 테이블의 두 구성 요소를 모두 저장하여 스트림/테이블 이중성 개념을 활용합니다. 테이블의 현재 상태는 RocksDB 를 사용하여 특정 서버에 로컬로 임시 저장됩니다 . 테이블에 적용된 일련의 변경 사항은 Kafka 주제에 영구적으로 저장되며 Kafka 브로커 전체에 복제됩니다. 테이블 구체화가 있는 ksqlDB 서버가 실패하면 새 서버가 Kafka 변경 로그에서 테이블을 다시 구체화합니다.
'ksqlDB' 카테고리의 다른 글
| ksql - 테이블 (0) | 2022.01.13 |
|---|---|
| ksql - Streams (0) | 2022.01.12 |
| ksqlDB - stream vs table (0) | 2022.01.12 |
| ksqlDB - Stream Processing (0) | 2022.01.12 |
| 도커로 ksqlDB 설치하기 (0) | 2022.01.11 |