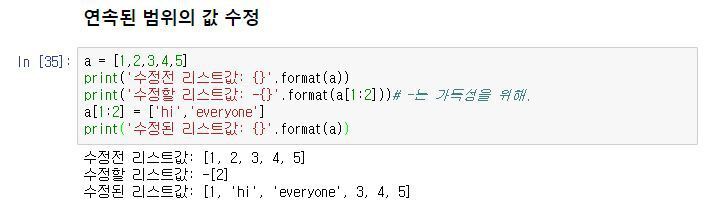
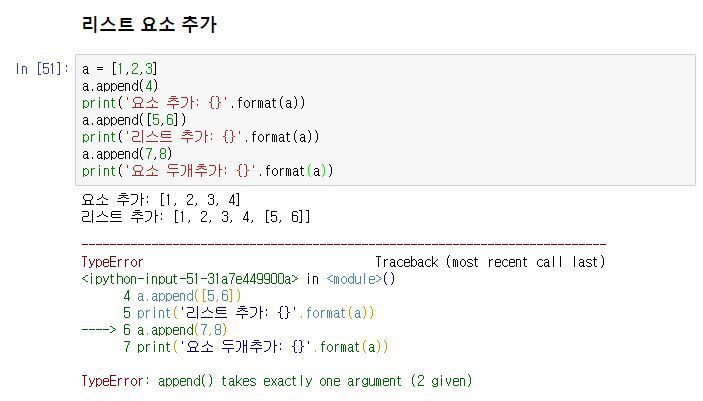
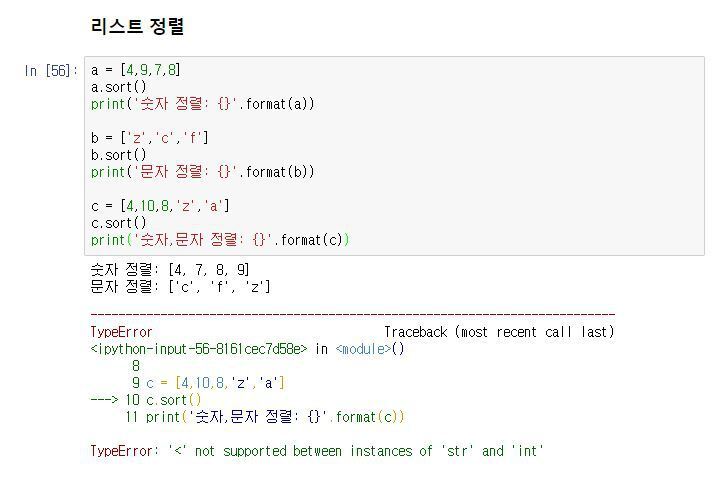
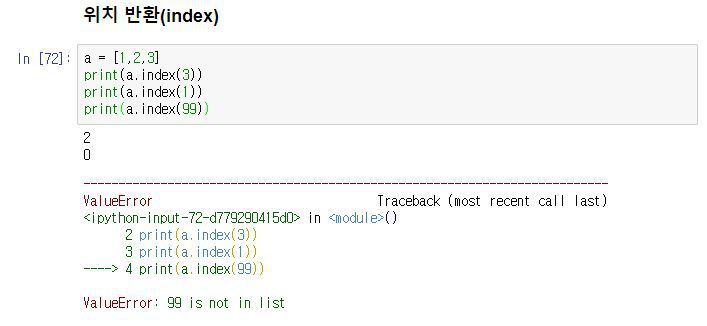
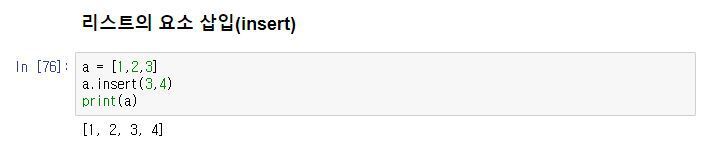
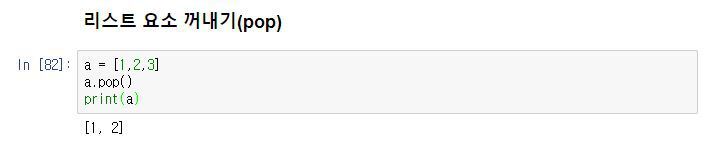
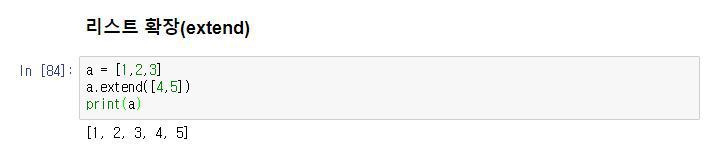
프로그램의 출력 표현 방법에는 여러 가지가 있습니다. 사람이 보기에 적합한 형태로 데이터를 인쇄할 수도 있고, 나중에 사용하기 위해 파일에 쓸 수도 있습니다.
7.1. 출력 포매팅
지금까지 우리는 값을 쓰는 두 가지 방법을 만났습니다: 표현식 문장 과 print() 함수입니다. (세 번째 방법은 파일 객체의 write() 메서드를 사용하는 것입니다; 표준 출력 파일은 sys.stdout 로 참조할 수 있습니다. 이것에 대한 자세한 정보는 라이브러리 레퍼런스를 보세요.)
종종 단순히 스페이스로 구분된 값을 인쇄하는 것보다 출력 형식을 더 많이 제어해야 하는 경우가 있습니다. 출력을 포맷하는 데는 여러 가지 방법이 있습니다.
- 포맷 문자열 리터럴을 사용하려면, 시작 인용 부호 또는 삼중 인용 부호 앞에 f 또는 F 를 붙여 문자열을 시작하십시오. 이 문자열 안에서, { 및 } 문자 사이에, 변수 또는 리터럴 값을 참조할 수 있는 파이썬 표현식을 작성할 수 있습니다.
-
>>>
year = 2016 event = 'Referendum' print(f'Results of the {year} {event}') print('Results of the {year} {event}') ## 실행결과 Results of the 2016 Referendum Results of the {year} {event} - 문자열의 str.format() 메서드는 더 많은 수작업을 요구합니다. 변수가 대체 될 위치를 표시하기 위해 { 및 }를 사용하고, 자세한 포매팅 디렉티브를 제공할 수 있지만, 포맷할 정보도 제공해야 합니다.
-
>>>
yes_votes = 42_572_654 no_votes = 43_132_495 percentage = yes_votes / (yes_votes + no_votes) print('{:-9} YES votes {:2.2%}'.format(yes_votes, percentage)) ## 실행결과 42572654 YES votes 49.67% - 마지막으로, 문자열 슬라이싱 및 이어붙이기 연산을 사용하여 상상할 수 있는 모든 배치를 만듦으로써, 모든 문자열 처리를 수행할 수 있습니다. 문자열형에는 주어진 열 너비로 문자열을 채우는 데 유용한 연산을 수행하는 몇 가지 메서드가 있습니다.
보기좋은 출력이 필요하지 않고 단지 디버깅을 위해 일부 변수를 빠르게 표시하려면, repr() 또는 str() 함수를 사용하여 모든 값을 문자열로 변환할 수 있습니다.
str() 함수는 어느 정도 사람이 읽기에 적합한 형태로 값의 표현을 돌려주게 되어있습니다. 반면에 repr() 은 인터프리터에 의해 읽힐 수 있는 형태를 만들게 되어있습니다 (또는 그렇게 표현할 수 있는 문법이 없으면 SyntaxError 를 일으키도록 구성됩니다). 사람이 소비하기 위한 특별한 표현이 없는 객체의 경우, str() 는 repr() 과 같은 값을 돌려줍니다. 많은 값, 숫자들이나 리스트와 딕셔너리와 같은 구조들, 은 두 함수를 쓸 때 같은 표현을 합니다. 특별히, 문자열은 두 가지 표현을 합니다.
몇 가지 예를 듭니다:
>>> s = 'Hello, world.'
>>> str(s)
'Hello, world.'
>>> repr(s)
"'Hello, world.'"
>>> str(1/7)
'0.14285714285714285'
>>> x = 10 * 3.25
>>> y = 200 * 200
>>> s = 'The value of x is ' + repr(x) + ', and y is ' + repr(y) + '...'
>>> print(s)
The value of x is 32.5, and y is 40000...
>>> # The repr() of a string adds string quotes and backslashes:
... hello = 'hello, world\n'
>>> hellos = repr(hello)
>>> print(hellos)
'hello, world\n'
>>> # The argument to repr() may be any Python object:
... repr((x, y, ('spam', 'eggs')))
"(32.5, 40000, ('spam', 'eggs'))"
string 모듈에는 문자열에 값을 치환하는 또 다른 방법을 제공하는 Template 클래스가 포함되어 있습니다. $x와 같은 자리 표시자를 사용하고 이것들을 딕셔너리에서 오는 값으로 치환하지만, 포매팅에 기능이 적습니다.
7.1.1. 포맷 문자열 리터럴
포맷 문자열 리터럴(간단히 f-문자열이라고도 합니다)은 문자열에 f 또는 F 접두어를 붙이고 표현식을 {expression}로 작성하여 문자열에 파이썬 표현식의 값을 삽입할 수 있게 합니다.
선택적인 포맷 지정자가 표현식 뒤에 올 수 있습니다. 이것으로 값이 포맷되는 방식을 더 정교하게 제어할 수 있습니다. 다음 예는 원주율을 소수점 이하 세 자리로 반올림합니다.
import math
print(f'The value of pi is approximately {math.pi:.3f}.')
## 실행결과
The value of pi is approximately 3.142.':' 뒤에 정수는 해당 필드의 최소 문자 폭이 됩니다. 줄 맞춤할 때 편리합니다.
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}
for name, phone in table.items():
print(f'{name:10} ==> {phone:10d}')
## 실행결과
Sjoerd ==> 4127
Jack ==> 4098
Dcab ==> 7678다른 수정자를 사용하면 포맷되기 전에 값을 변환할 수 있습니다. '!a'는 ascii()를, '!s'는 str()을, '!r'는 repr()을 적용합니다.:
animals = 'eels'
print(f'My hovercraft is full of {animals}.')
My hovercraft is full of eels.
print(f'My hovercraft is full of {animals!r}.')
My hovercraft is full of 'eels'.이러한 포맷 사양에 대한 레퍼런스는 포맷 명세 미니 언어에 대한 레퍼런스 지침서를 참조하십시오.
7.1.2. 문자열 format() 메서드
str.format() 메서드의 기본적인 사용법은 이런 식입니다:
print('We are the {} who say "{}!"'.format('knights', 'Ni'))
## 실행결과
We are the knights who say "Ni!"중괄호와 그 안에 있는 문자들 (포맷 필드라고 부른다) 은 str.format() 메서드로 전달된 객체들로 치환됩니다. 중괄호 안의 숫자는 str.format() 메서드로 전달된 객체들의 위치를 가리키는데 사용될 수 있습니다.
>>> print('{0} and {1}'.format('spam', 'eggs'))
spam and eggs
>>> print('{1} and {0}'.format('spam', 'eggs'))
eggs and spam
str.format() 메서드에 키워드 인자가 사용되면, 그 값들은 인자의 이름을 사용해서 지정할 수 있습니다.
print('This {food} is {adjective}.'.format(food='spam', adjective='absolutely horrible'))
This spam is absolutely horrible.위치와 키워드 인자를 자유롭게 조합할 수 있습니다:
print('The story of {0}, {1}, and {other}.'.format('Bill', 'Manfred',other='Georg'))
The story of Bill, Manfred, and Georg.나누고 싶지 않은 정말 긴 포맷 문자열이 있을 때, 포맷할 변수들을 위치 대신에 이름으로 지정할 수 있다면 좋을 것입니다. 간단히 딕셔너리를 넘기고 키를 액세스하는데 대괄호 '[]' 를 사용하면 됩니다.
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; ' 'Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678〈**〉 표기법을 사용해서 table을 키워드 인자로 전달해도 같은 결과를 얻을 수 있습니다.
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678이 방법은 모든 지역 변수들을 담은 딕셔너리를 돌려주는 내장 함수 vars() 와 함께 사용할 때 특히 쓸모가 있습니다.
예를 들어, 다음 줄은 정수와 그 제곱과 세제곱을 제공하는 빽빽하게 정렬된 열 집합을 생성합니다:
for x in range(1, 11):
print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000str.format() 를 사용한 문자열 포매팅의 완전한 개요는 포맷 문자열 문법 을 보세요.
7.1.3. 수동 문자열 포매팅
여기 같은 제곱수와 세제곱수 표를 수동으로 포매팅했습니다:
for x in range(1, 11):
print(repr(x).rjust(2), repr(x*x).rjust(3), end=' ')
# Note use of 'end' on previous line
print(repr(x*x*x).rjust(4))
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000(print() 의 동작 방식으로 인해 각 칼럼 사이에 스페이스 하나가 추가되었음에 유의하세요: 항상 인자들 사이에 스페이스를 추가합니다.)
문자열 객체의 str.rjust() 메서드는 왼쪽에 스페이스를 채워서 주어진 폭으로 문자열을 우측 줄 맞춤합니다. 비슷한 메서드 str.ljust() 와 str.center() 도 있습니다. 이 메서드들은 어떤 것도 출력하지 않습니다, 단지 새 문자열을 돌려줍니다. 입력 문자열이 너무 길면, 자르지 않고, 변경 없이 그냥 돌려줍니다; 이것이 열 배치를 엉망으로 만들겠지만, 보통 값에 대해 거짓말을 하게 될 대안보다는 낫습니다. (정말로 잘라내기를 원한다면, 항상 슬라이스 연산을 추가할 수 있습니다, x.ljust(n)[:n] 처럼.)
다른 메서드도 있습니다, str.zfill(). 숫자 문자열의 왼쪽에 0을 채웁니다. 플러스와 마이너스 부호도 이해합니다:
print('12'.zfill(5))
'00012'
print('-3.14'.zfill(7))
'-003.14'
print('3.14159265359'.zfill(5))
'3.14159265359'
7.1.4. 예전의 문자열 포매팅
% 연산자(모듈로)는 문자열 포매팅에도 사용할 수 있습니다. 'string' % values가 주어지면, string에 있는 % 인스턴스는 0개 이상의 values 요소로 대체됩니다. 이 연산을 흔히 문자열 보간(interpolation)이라고 합니다. 예를 들면:
import math
print('The value of pi is approximately %5.3f.' % math.pi)
The value of pi is approximately 3.142.더 자세한 내용은 printf 스타일 문자열 포매팅 섹션에 나옵니다.
7.2. 파일을 읽고 쓰기
Syntax : open(filename, mode)
텍스트 파일을 열 때에는 open 명령어를 사용한다. 기본적으로 '변수(개체이름) = open("파일명")' 형태로 코딩한다. 파일의 특정 위치(폴더)를 지정하지 않으면 python을 실행한 폴더에서 찾습니다.
mode는 쓰기모드 'w', 읽기모든 'r', 읽기쓰기모드 'r+', binary 모드는 'b' 로 표기합니다. 값을 주지않으면 디폴트는 'r'입니다.
>>> f = open('workfile', 'w')
첫 번째 인자는 파일 이름의 문자열입니다. 두 번째 인자는 파일이 사용될 방식의 문자열입니다. mode 는 파일을 읽기만 하면 'r', 쓰기만 하면 'w' (같은 이름의 이미 존재하는 파일은 삭제됩니다) 가 되고, 'a' 는 파일을 덧붙이기 위해 엽니다; 파일에 기록되는 모든 데이터는 자동으로 끝에 붙습니다. 'r+' 는 파일을 읽고 쓰기 위해 엽니다. mode 인자는 선택적인데, 생략하면 'r' 이 가정됩니다.
보통, 파일은 텍스트 모드 (text mode) 로 열리는데, 이 뜻은, 파일에 문자열을 읽고 쓰고, 파일에는 특정한 인코딩으로 저장된다는 것입니다. 인코딩이 지정되지 않으면 기본값은 플랫폼 의존적입니다. mode 에 'b' 는 파일을 바이너리 모드 (binary mode)로 엽니다. 데이터는 바이트열 객체의 형태로 읽고 쓰입니다. 텍스트를 포함하지 않는 모든 파일에는 이 모드를 사용해야 합니다.
텍스트 모드에서, 읽을 때의 기본 동작은 플랫폼 의존적인 줄 종료 (유닉스에서 \n, 윈도우에서 \r\n) 를 \n 로 변경하는 것입니다. 텍스트 모드로 쓸 때, 기본 동작은 \n 를 다시 플랫폼 의존적인 줄 종료로 변환합니다. 텍스트 파일의 경우는 문제가 안 되지만, JPEG 이나 EXE 파일과 같은 바이너리 데이터가 깨지게 됩니다. 그런 파일을 읽고 쓸 때 바이너리 모드를 사용합니다.
파일 객체를 다룰 때 with 키워드를 사용하는 것이 좋은 습관입니다. with를 쓰면 도중 예외가 발생하더라도 파일이 올바르게 닫힙니다. with 를 사용하는 것은 try-finally 블록을 쓰는 것에 비교해 훨씬 간결합니다.
with open('workfile') as f:
read_data = f.read()
# We can check that the file has been automatically closed.
f.closed
Truewith 키워드를 사용하지 않으면, f.close() 를 호출해서 파일을 닫고 사용된 시스템 자원을 즉시 반납해야 합니다.
with 키워드를 사용하거나 f.close()를 호출하지 않고 f.write()를 호출하면 프로그램이 성공적으로 종료되더라도 f.write()의 인자가 디스크에 완전히 기록되지 않을 수 있습니다.
파일 객체가 닫힌 후에 with 문이나 f.close() 를 호출하는 경우에 파일 객체를 사용하려면 실패합니다.
f.close()
f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: I/O operation on closed file.7.2.1. 파일 객체의 매소드
이 섹션의 나머지 예들은 f 라는 파일 객체가 이미 만들어졌다고 가정합니다.
파일의 내용을 읽으려면, f.read(size) 를 호출하는데, 일정량의 데이터를 읽고 문자열 (텍스트 모드 에서) 이나 바이트열 (바이너리 모드에서) 로 돌려줍니다. size 는 선택적인 숫자 인자입니다. size 가 생략되거나 음수면 파일의 내용 전체를 읽어서 돌려줍니다; 파일의 크기가 기계의 메모리보다 크다면 시스템에 문제가 발생할 수 있습니다. 그렇지 않으면 최대 size 문자(텍스트 모드에서)나 size 바이트(바이너리 모드에서)를 읽고 돌려줍니다. 파일의 끝에 도달하면, f.read() 는 빈 문자열 ('') 을 돌려줍니다.
>>> f.read()
'This is the entire file.\n'
>>> f.read()
''
f.readline() 은 파일에서 한 줄을 읽습니다; 개행 문자 (\n) 는 문자열의 끝에 보존되고, 파일이 개행문자로 끝나지 않는 때에만 파일의 마지막 줄에서만 생략됩니다. 이렇게 반환 값을 모호하지 않게 만듭니다; f.readline() 가 빈 문자열을 돌려주면, 파일의 끝에 도달한 것이지만, 빈 줄은 '\n', 즉 하나의 개행문자만을 포함하는 문자열로 표현됩니다.
f.readline()
'This is the first line of the file.\n'
f.readline()
'Second line of the file\n'
f.readline()파일에서 줄들을 읽으려면, 파일 객체에 대해 루핑할 수 있습니다. 이것은 메모리 효율적이고, 빠르며 간단한 코드로 이어집니다:
for line in f:
print(line, end='')
This is the first line of the file.
Second line of the file파일의 모든 줄을 리스트로 읽어 들이려면 list(f) 나 f.readlines() 를 쓸 수 있습니다.
f.write(string) 은 string 의 내용을 파일에 쓰고, 쓴 문자들의 개수를 돌려줍니다.
f.write('This is a test\n')
15다른 형의 객체들은 문자열 (텍스트 모드에서) 이나 바이트열 객체 (바이너리 모드에서) 로 쓰기 전에 변환될 필요가 있습니다
value = ('the answer', 42)
s = str(value) # convert the tuple to string
f.write(s)
18f.tell() 은 파일의 현재 위치를 가리키는 정수를 돌려주는데, 바이너리 모드의 경우 파일의 처음부터의 바이트 수로 표현되고 텍스트 모드의 경우는 불투명한 숫자입니다.
파일 객체의 위치를 바꾸려면, f.seek(offset, whence) 를 사용합니다. 위치는 기준점에 offset 을 더해서 계산됩니다; 기준점은 whence 인자로 선택합니다. whence 값이 0이면 파일의 처음부터 측정하고, 1이면 현재 파일 위치를 사용하고, 2 는 파일의 끝을 기준점으로 사용합니다. whence 는 생략될 수 있고, 기본값은 0이라서 파일의 처음을 기준점으로 사용합니다.
f = open('workfile', 'rb+')
f.write(b'0123456789abcdef')
16
f.seek(5) # Go to the 6th byte in the file
5
f.read(1)
b'5'
f.seek(-3, 2) # Go to the 3rd byte before the end
13
f.read(1)
b'd'텍스트 파일에서는 파일 시작에 상대적인 위치 변경만 허락되고 (예외는 seek(0, 2) 를 사용해서 파일의 끝으로 위치를 변경하는 경우입니다), 올바른 offset 값은 f.tell() 이 돌려준 값과 0뿐입니다. 그 밖의 다른 offset 값은 정의되지 않은 결과를 낳습니다.
파일 객체는 isatty() 나 truncate() 같은 몇 가지 메서드가 더 있습니다. 파일 객체에 대한 완전한 안내는 라이브러리 레퍼런스를 참조하세요.
7.2.2. json 으로 구조적인 데이터를 저장하기
문자열은 파일에 쉽게 읽고 쓸 수 있습니다. 숫자는 약간의 변형을 해야 하는데, read() 메서드가 문자열만을 돌려주기 때문입니다. 이 문자열을 int() 같은 함수로 전달해야만 하는데, '123' 같은 문자열을 받고 숫자 값 123을 돌려줍니다. 중첩된 리스트나 딕셔너리 같은 더 복잡한 데이터를 저장하려고 할 때, 수작업으로 파싱하고 직렬화하는 것이 까다로울 수 있습니다.
사용자가 반복적으로 복잡한 데이터형을 파일에 저장하는 코드를 작성하고 디버깅하도록 하는 대신, 파이썬은 JSON (JavaScript Object Notation) 이라는 널리 쓰이는 데이터 교환 형식을 사용할 수 있게 합니다. json 이라는 표준 모듈은 파이썬 데이터 계층을 받아서 문자열 표현으로 바꿔줍니다; 이 절차를 직렬화 (serializing) 라고 부릅니다. 문자열 표현으로부터 데이터를 재구성하는 것은 역 직렬화 (deserializing) 라고 부릅니다. 직렬화와 역 직렬화 사이에서, 객체를 표현하는 문자열은 파일이나 데이터에 저장되거나 네트워크 연결을 통해 원격 기계로 전송될 수 있습니다.
참고
JSON 형식은 데이터 교환을 위해 응용 프로그램들이 자주 사용합니다. 많은 프로그래머가 이미 이것에 익숙하므로, 연동성을 위한 좋은 선택이 됩니다.
객체 x 가 있을 때, 간단한 한 줄의 코드로 JSON 문자열 표현을 볼 수 있습니다:
import json
x = [1, 'simple', 'list']
print(json.dumps(x))
## 실행결과
[1, "simple", "list"]dump()함수는 dumps() 함수의 변형이고 객체를 텍스트 파일 로 직렬화합니다. 그래서 f 가 쓰기를 위해 열린 텍스트 파일 이면, 다음과 같이 할 수 있습니다.
json.dump(x, f)
객체를 다시 디코드하려면, f 가 읽기를 위해 열린 텍스트 파일 객체일 때:
x = json.load(f)
직렬화로 리스트와 딕셔너리를 다룰 수 있지만, 임의의 클래스 인스턴스를 JSON 으로 직렬화하기 위해서는 약간의 수고가 더 필요합니다. json 모듈의 레퍼런스는 이 방법에 대한 설명을 담고 있습니다.
3 입력
3.1. input 함수
Python에서는 표준 입력 함수로 input 함수를 지원합니다.
일단 도움말을 통해서 input 함수의 사용법을 알아보도록 하겠습니다.
Ex12_input0.py
# 표준 입력
# input함수의 도움말을 확인해 보자
help(input)실행 결과
Help on built-in function input in module builtins:
input(prompt=None, /)
Read a string from standard input. The trailing newline is stripped.
The prompt string, if given, is printed to standard output without a
trailing newline before reading input.
If the user hits EOF (*nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError.
On *nix systems, readline is used if available.위의 도움말을 보면 input함수의 사용법은 다음과 같습니다.
- 표준 입력에서 문자열을 읽습니다. 후행 줄 바꿈이 제거됩니다.
- 프롬프트 문자열이 주어진 경우, 입력을 읽기 전에 후행 개행 표시 없이 표준 출력으로 인쇄됩니다.
- 사용자가 EOF(*nix: Ctrl-D, Windows: Ctrl-Z+Return)를 누르면 EOFError를 발생시킵니다.
- *nix 시스템에서 사용 가능한 경우 readline이 사용됩니다.
Ex13_input1.py
# 표준 입력
print('이름을 입력하세요', end="")
name = input();
print("이름 : {0}, type : {1}".format(name,type(name)))
name = input('이름을 입력하세요 ');
print("이름 : {0}, type : {1}".format(name,type(name)))
name = input('아무것도 입력하지 말고 EOF(Ctrl+D 또는 Ctrl+Z+Enter)를 입력해보세요');실행 결과
이름을 입력하세요 한사람
이름 : 한사람, type : <class 'str'>
이름을 입력하세요 두사람
이름 : 두사람, type : <class 'str'>
아무것도 입력하지 말고 EOF(Ctrl+D 또는 Ctrl+Z+Enter)를 입력해보세요^D
Traceback (most recent call last):
File "C:/PyThonProjects/Ex01/basic03/Ex13_input1.py", line 7, in <module>
name = input('아무것도 입력하지 말고 EOF(Ctrl+D 또는 Ctrl+Z+Enter)를 입력해보세요');
EOFError: EOF when reading a line"이름을 입력하세요"라고 나오면 "한사람"을 입력하세요
"이름을 입력하세요"라고 나오면 "두사람"을 입력하세요
"아무것도 입력하지 말고 EOF(Ctrl+D 또는 Ctrl+Z+Enter)를 입력해보세요"라고 나오면 윈도우인 경우 Ctrl키와 Z키를 같이 눌러 보세요
2. 정수 입력
기본적으로 input함수는 문자열로 입력됩니다.
그래서 입력받은 값을 정수형으로 변환해서 사용해야 합니다.
- eval() 함수 : 인수를 유효한 파이썬 표현식으로 리턴 합니다.
- int() 클래스 : class int(x=0), class int(x,base=10)
숫자나 문자열 x 로 부터 만들어진 정수 객체를 돌려줍니다.
인자가 주어지지 않으면 0 을 돌려줍니다.
base는 진법을 나타내며 주로 2, 8, 10, 16을 사용합니다. 10이 기본값입니다.
Ex14_input2.py
# 표준 입력
data = input("정수를 입력하시오 : ")
print(data, type(data))
# print(data, type(data), data + 1) 에러 문자열과 정수를 +(더하기)할 수 없습니다.
data = eval(input("정수를 입력하시오 : "))
print(data, type(data), data + 1)
data = int(input("정수를 입력하시오 : "))
print(data, type(data), data + 1)
data = int(input("2진수를 입력하시오 : "), 2)
print(data, type(data), data + 1)
data = int(input("8진수를 입력하시오 : "), 8)
print(data, type(data), data + 1)
data = int(input("10진수를 입력하시오 : "), 10)
print(data, type(data), data + 1)
data = int(input("16진수를 입력하시오 : "), 16)
print(data, type(data), data + 1)
실행 결과
정수를 입력하시오 : 1
1 <class 'str'>
정수를 입력하시오 : 2
2 <class 'int'> 3
정수를 입력하시오 : 3
3 <class 'int'> 4
2진수를 입력하시오 : 1010
10 <class 'int'> 11
8진수를 입력하시오 : 10
8 <class 'int'> 9
10진수를 입력하시오 : 10
10 <class 'int'> 11
16진수를 입력하시오 : 1a
26 <class 'int'> 27
실행할 때 차례대로 1, 2, 3, 1010, 10, 10, 1a를 입력해보세요
3. 실수 입력
기본적으로 input함수는 문자열로 입력됩니다.
그래서 입력받은 값을 실수형으로 변환해서 사용해야 합니다.
- eval() 함수 : 인수를 유효한 파이썬 표현식으로 리턴 합니다.
- float() 클래스 : class float(x)
숫자나 문자열 x 로 부터 만들어진 실수 객체를 돌려줍니다.
인자가 주어지지 않으면 0 을 돌려줍니다.
Ex15_input3.py
# 표준 입력
data = input("실수를 입력하시오 : ")
print(data, type(data))
# 에러 문자열과 실수를 +(더하기)할 수 없습니다.
# print(data, type(data), data + 1.2)
data = eval(input("실수를 입력하시오 : "))
print(data, type(data), data + 1.2)
data = float(input("정수를 입력하시오 : "))
print(data, type(data), data + 1.2)
실행 결과
실수를 입력하시오 : 3.14
3.14 <class 'str'>
실수를 입력하시오 : 3.14
3.14 <class 'float'> 4.34
정수를 입력하시오 : 3.14
3.14 <class 'float'> 4.34
4. 튜플(tuple), 리스트(list)로 입력받기
기본적으로 input함수는 문자열로 입력됩니다.
- eval() 함수 : 인수를 유효한 파이썬 표현식으로 리턴 합니다.
Ex16_input4.py
# 표준 입력
string = input("(1,2) 처럼입력하시오 ")
print(string, type(string))
string = eval( input("(1,2) 처럼입력하시오 "))
print(string, type(string))
string = input("[1,2,3,4,5,6] 처럼입력하시오 ")
print(string, type(string))
string = eval( input("[1,2,3,4,5,6] 처럼입력하시오 "))
print(string, type(string))
실행 결과
(1,2) 처럼입력하시오 (1,2)
(1,2) <class 'str'>
(1,2) 처럼입력하시오 (1,2)
(1, 2) <class 'tuple'>
[1,2,3,4,5,6] 처럼입력하시오 [1,2,3]
[1,2,3] <class 'str'>
[1,2,3,4,5,6] 처럼입력하시오 [1,2,3]
[1, 2, 3] <class 'list'>
'Python' 카테고리의 다른 글
| Python - 표준라이브러리 II (0) | 2022.01.06 |
|---|---|
| Python - 오류 및 예외 (0) | 2022.01.06 |
| Python - module (0) | 2022.01.06 |
| Python - class (0) | 2022.01.06 |
| python - decorator (0) | 2022.01.05 |