UI for Apache Kafka is a free, open-source web UI to monitor and manage Apache Kafka clusters.
Apache Kafka용 UI는 Apache Kafka 클러스터를 모니터링하고 관리하기 위한 무료 오픈 소스 웹 UI입니다. 대시보드를 사용하면 브로커, 주제, 파티션, consumer와 같은 Kafka 클러스터의 메트릭을 추적할 수 있습니다. Apache Kafka용 UI는 Kafka 데이터를 시각화합니다. 로컬 또는 클라우드에서 실행할 수 있습니다.
특징
다중 클러스터 관리 — 모든 클러스터를 한 곳에서 모니터링 및 관리
메트릭 대시보드를 통한 성능 모니터링 — 대시보드로 주요 Kafka 메트릭 추적
Kafka Broker 보기 — 주제 및 파티션 할당, 컨트롤러 상태 보기
Kafka 주제 보기 — 파티션 수, 복제 상태 및 사용자 정의 구성 보기
소비자 그룹 보기 — 파티션별 고정 오프셋, 결합 및 파티션별 지연 보기
메시지 찾아보기 — JSON, 일반 텍스트 및 Avro 인코딩으로 메시지 찾아보기
동적 주제 구성 — 동적 구성으로 새 주제 생성 및 구성
구성 가능한 인증 — Github/Gitlab/Google OAuth 2.0(옵션)으로 설치 보안
시작하기
Apache Kafka용 UI를 실행하려면 사전 빌드된 Docker 이미지를 사용하거나 로컬에 빌드할 수 있습니다.
[ 수행환경 ]
- Microsoft Windows 10 Pro(10.0.19041 N/A 빌드 19041)
위와 같이 환경변수를 설정했을 때, 카프카 UI 접속 시 UI 화면은 보이지만, borker, topic 등에 대한 정보가 정상적으로 보이지 않았습니다. 그래서 2가지를 수정했는데, 수정 후 재기동 하니 정상적으로 보였습니다.
첫번 째 수정한 부분
카프카 브로커의 server.properties 에서 listeners 내용을 수정했습니다.
기존 0.0.0.0 에서 WSL 의 IP Address로 변경했습니다. 수정 후 카프카 브로커를 재기동합니다.
# listeners=PLAINTEXT://0.0.0.0:9092
## 아래처럼 WSL IP Address로 수정
listeners=PLAINTEXT://172.24.121.239:9092
두번 째 수정한 부분
카프카 UI 의 환경변수 중 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=0.0.0.0:9092 부분을 KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=172.24.118.82:9093 로 수정했습니다. 여기서의 IP는 WSL 의 IP 이자 카프카 브로커에서 설정한 listeners IP와 동일한 IP 입니다.
수정 후 실행된 컨테이너가 있으면 중지시키고 카프카 UI 컨테이너를 실행합니다.
여기에서 8080 port가 사용 중이라고 나올 경우, 카프카 브로커에서 admin port를 사용할 가능성이 크므로 카프카 브로커의 admin port를 변경하던지, UI 컨테이너의 앞 쪽 port를 변경합니다. 필자의 경우에 port 충돌이 발생해서 카프카 브로커의 admin port를 disable 시켰습니다.
foreground로 실행되니 최종 "Creating new log file" 보이면 다음 단계를 진행합니다.
[2022-01-01 00:34:06,106] INFO ______ _ (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,107] INFO |___ / | | (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,107] INFO / / ___ ___ | | __ ___ ___ _ __ ___ _ __ (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,108] INFO / / / _ \ / _ \ | |/ / / _ \ / _ \ | '_ \ / _ \ | '__| (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,108] INFO / /__ | (_) | | (_) | | < | __/ | __/ | |_) | | __/ | | (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,109] INFO /_____| \___/ \___/ |_|\_\ \___| \___| | .__/ \___| |_| (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,109] INFO | | (org.apache.zookeeper.server.ZooKeeperServer)
[2022-01-01 00:34:06,110] INFO |_| (org.apache.zoo
..... .....
[2022-01-01 00:34:10,369] INFO Using checkIntervalMs=60000 maxPerMinute=10000 maxNeverUsedIntervalMs=0 (org.apache.zookeeper.server.ContainerManager)
[2022-01-01 00:34:10,373] INFO ZooKeeper audit is disabled. (org.apache.zookeeper.audit.ZKAuditProvider)
[2022-01-01 01:08:12,522] INFO Creating new log file: log.1 (org.apache.zookeeper.server.persistence.FileTxnLog)
[2022-01-01 01:08:14,923] WARN fsync-ing the write ahead log in SyncThread:0 took 2389ms which will adversely effect operation latency.File size is 67108880 bytes. See the ZooKeeper troubleshooting guide (org.apache.zookeeper.server.persistence.FileTxnLog)
config/zookeeper.properties 파일을 보면 clientPort 속성이 2181로 설정된 것을 볼 수 있습니다. 이 속성은 Zookeeper 서버가 현재 수신 대기 중인 포트입니다.
# File: kafka_2.13-3.0.0/config/zookeeper.properties
# the port at which the clients will connect
clientPort=2181
Kafka Broker 실행하기
Kafka 브로커는 클러스터의 핵심이며 데이터가 저장되고 배포되는 파이프라인 역할을 합니다. Zookeeper를 시작한 방법과 유사하게,
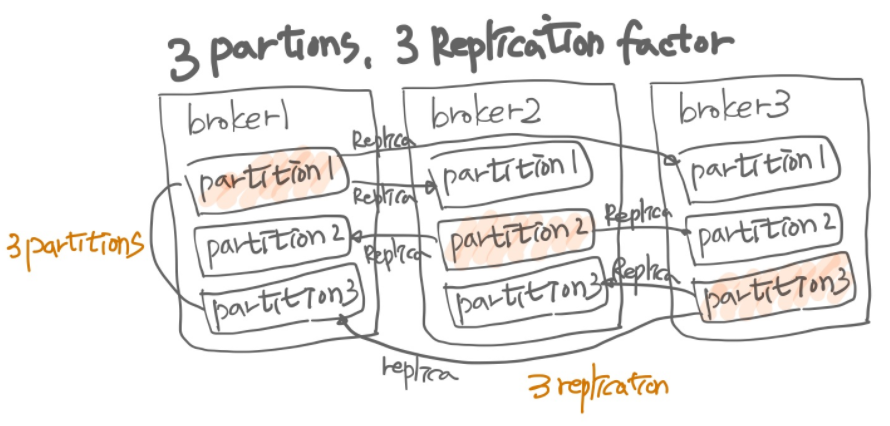
브로커 서버를 시작하고(bin/kafka-server-start.sh) 구성(config/server.properties)하기 위한 두 개의 파일이 있습니다. kafka의 분산환경 구성을 해야하기 때문에 다이어그램과 같이 3개의 브로커를 시작하겠습니다. config/server.properties 파일을 열면 여러 구성 옵션이 표시됩니다(지금은 대부분 무시할 수 있음). 그러나 각 브로커 인스턴스에 대해 고유해야 하는 세 가지 속성이 있습니다.
File: kafka_2.13-3.0.0/config/server.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
# The address the socket server listens on. It will get the value returned from
listeners=PLAINTEXT://:9092
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kafka-logs
zookeeper.connect=localhost:2181
* 주키퍼 서버들 멀티로 구성한 경우에는 zookeeper.connect 에 나열해주면 됩니다.
주제의 파티션 및 복제본에 대한 세부 정보를 출력합니다. Partition, Leader/follower, Replicas, Isr(In Sync Replica) 정보를 보여줍니다. 여기서 ISR은 kafka 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태를 나타냅니다. 만일, 브로커 중 1대의 서버가 중지된 상태라면 Isr 은 2개 만 표시됩니다. 3번 브로커 서버가 중지되었다면 Leader는 1 또는 2가 되고 Isr 은 1,2 가 됩니다.
KIP-226(Kafka Improvement Proposal)은 브로커 구성의 동적 업데이트에 대한 지원을 추가했습니다. 브로커를 다시 시작하지 않고 클러스터에서 주제를 동적으로 삭제할 수 있도록 허용합니다.(동적 허용을 하지 않으려면 server.properties 구성에서 "delete.topic.enable" 구성을 "false"로 설정하면 됩니다.)
Caused by: org.apache.kafka.common.errors.InvalidRequestException: Invalid config value for resource ConfigResource(type=BROKER, name=''): Cannot update these configs dynamically: Set(delete.topic.enable)
2.
Exception in thread "main" joptsimple.UnrecognizedOptionException: zookeeper is not a recognized option at joptsimple.OptionException.unrecognizedOption(OptionException.java:108)
3.
Invalid config(s): delete.topic.enable
아직 동적 config 설정이 정상작동 하지 않는 것 같다. 패치버전이나 더 상위 버전이 나오는 다시 확인해 본다.
Zookeeper 쉘을 이용한 방법
* 주키퍼로 삭제할지 말고 kafka-topics.sh 로 삭제하는 것을 권장합니다. 주키퍼는 znode 관리용입니다.
zookeeper-shell.sh 를 이용하여서 znode를 삭제할 수 있습니다.
rmr명령은 더이상 사용되진 않는다. delete나 deleteall로 삭제합니다. delete 를 사용할 경우 message가 남아있는 경우 삭제가 되지 않습니다. 이럴 경우, deleteall로 삭제할 수 있습니다.
$ bin/zookeeper-shell.sh localhost:2181
ls /brokers/topics
## 실행결과
[__consumer_offsets, movie, music, my-kafka-topic]
rmr /brokers/topics/my-kafka-topic
## 실행결과. rmr은 사용할 수 없다.
Command not found: Command not found rmr
## The zkCli provides the rmr (deprecated) or deleteall command for this purpose
delete /brokers/topics/my-kafka-topic
## 실행결과
Node not empty: /brokers/topics/my-kafka-topic
deleteall /brokers/topics/my-kafka-topic
ls /brokers/topics
[__consumer_offsets, movie, music]
quit
## 삭제된 topic을 다시 생성해본다.
$ bin/kafka-topics.sh --create --topic my-kafka-topic --bootstrap-server localhost:9093 --partitions 3 --replication-factor 2
## 오류가 발생한다. topic을 kafka-topics.sh 로 조회하면 목록이 보인다.
## zookeeper와 kafka broker 간이 연동이 잘 안되는 것 같다.
Error while executing topic command : Topic 'my-kafka-topic' already exists
* 주키퍼로 삭제할지 말고 kafka-topics.sh 로 삭제하는 것을 권장합니다. 주키퍼는 znode 관리용입니다.
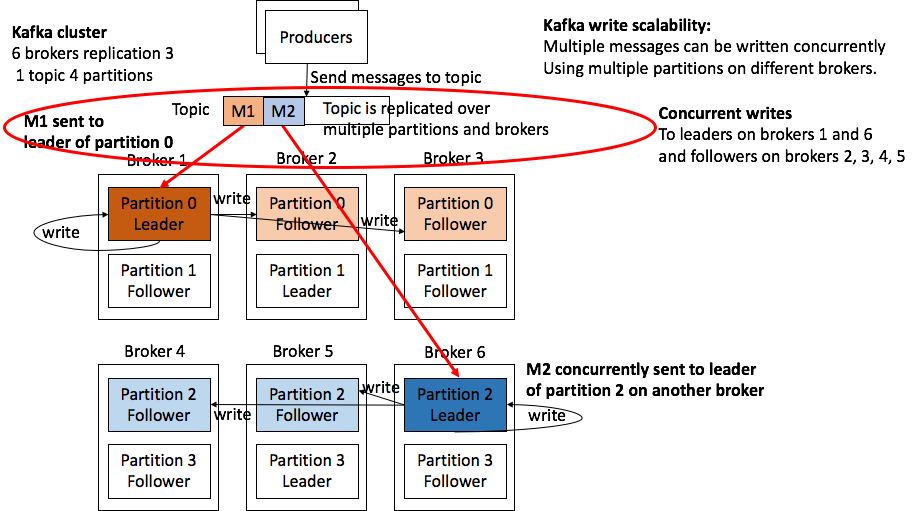
Producers: Topic에 메시지 보내기
"생산자(Producer)"는 데이터를 Kafka 클러스터에 넣는 프로세스입니다.
bin 디렉토리의 명령어는 콘솔에 텍스트를 입력할 때마다 클러스터에 데이터를 입력하는 콘솔 생성자(Producer)를 제공합니다.
이제 데이터를 입력하고 Enter 키를 치면, Kafka 클러스터에 텍스트를 입력할 수 있는 명령 프롬프트가 표시됩니다.
컨슈머가 데이터를 가져가도 Topic 데이터는 삭제되지 않습니다.
>first insert
>두번째 입력
프로듀서가 데이터를 보낼 때 '파티션키'를 지정해서 보낼 수 있습니다.
파티션키를 지정하지 않으면, 라운드로빈 방식으로 파티션에 저장하고,
파티션키를 지정하면, 파티셔너가 파티션키의 HASH 값을 구해서 특정 파티션에 할당합니다.
카프카에서 kafka-console-producer.sh로 Consumer에게 메세지를 보낼 때 기본적으로 key값이 null로 설정되어 있습니다. 이럴 때 설정에서 parse.key 및 key.separator 속성을 설정하면 key와 value가 포함된 메시지를 보낼 수 있습니다.
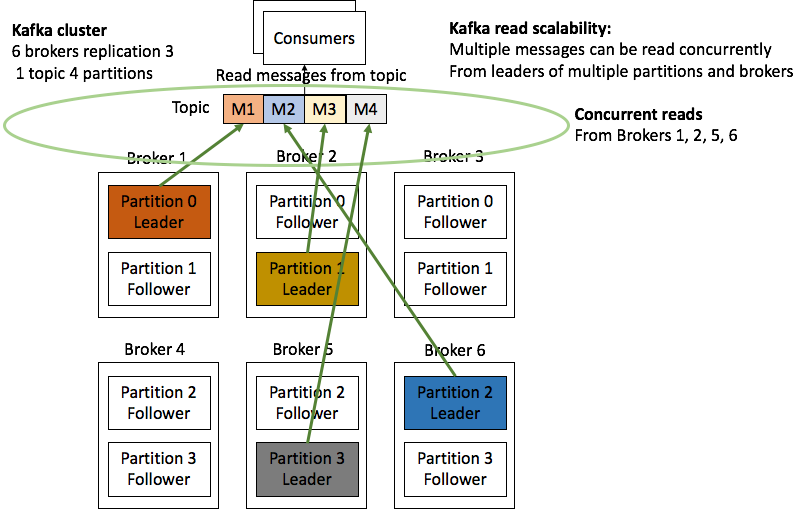
Kafka consumers 를 사용하여 클러스터에서 데이터를 읽을 수 있습니다. 이 경우 이전 섹션에서 생성한 데이터를 읽습니다. consumer를 시작하려면 다음 명령을 실행합니다. 아래와 같이 위에서 pruducer가 입력한 데이터가 출력됩니다.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic my-kafka-topic --from-beginning
first insert
두번째 입력
bootstrap-server는 클러스터의 브로커 중 하나일 수 있습니다.
Topic은 생산자가 클러스터에 데이터를 입력한 Topic(주제)과 동일해야 합니다.
from-beginning은 클러스터에 현재 가지고 있는 모든 메시지를 원한다고 클러스터에 알립니다.
컨슈머 그룹이 다른 새로운 컨슈머가 auto.offset.reset=earliest 설정으로 데이터를 0번부터 가져갈 수 있습니다. 설정하지 않으면 새롭게 토픽에 생성된 메세지만 읽어옵니다.
위의 명령을 실행하면 콘솔에 로그온한 생산자가 입력한 모든 메시지가 즉시 표시됩니다. 소비자가 실행되는 동안 생산자가 메시지를 입력하면 실시간으로 콘솔에 출력되는 것을 볼 수 있습니다.
이런 식으로 Kafka는 지속적인 메시지 대기열처럼 작동하여 소비자가 아직 읽지 않은 메시지를 저장하고 소비자가 실행되는 동안 새 메시지가 오는 대로 전달합니다.
카프카에서는 consumer 그룹이라는 개념이 있는데 --consumer-property group.id=group-01 형식으로 consumer 그룹을 지정할 수 있습니다. 카프카 브로커는 컨슈머 그룹 중 하나의 컨슈머에게만 이벤트를 전달합니다. 동일한 이벤트 처리를 하는 컨슈머를 clustering 한 경우에 컨슈머 그룹으로 지정하면 클러스터링된 컨슈머 중 하나의 서버가 데이터를 수신합니다.
key와 value를 콘솔창에 표시하기 위해서는 --property print.key=true --property key.separator=: 를 설정합니다.
기존의 Message Queue 솔루션에서는 컨슈머가 메시지를 가져가면, 해당 메세지를 큐에서 삭제된다. 즉, 하나의 큐에 대하여 여러 컨슈머가 붙어서 같은 메세지를 컨슈밍할 수 없다. 하지만 Kafka는, 컨슈머가 메세지를 가져가도 큐에서 즉시 삭제되지 않으며, 하나의 토픽에 여러 컨슈머 그룹이 붙어 메세지를 가져갈 수 있다.
또한 각 consumer group마다 해당 topic의 partition에 대한 별도의 offset을 관리하고, group에 컨슈머가 추가/제거 될 때마다 rebalancing을 하여 group 내의 consumer에 partition을 할당하게 된다. 이는 컨슈머의 확장/축소를 용이하게 하고, 하나의 MQ(Message Queue)를 컨슈머 별로 다른 용도로 사용할 수 있는 확장성을 제공한다.
reset-offsets의 옵션으로 --to-earlist , --to-datetime, --from-file, --to-current, --shift-by 등이 있다 - --shift-by -2 를 하면 오프셋이 2칸 전으로 이동한다
execute의 옵션으로 --all-topics 와 --topic [그룹 이름] 이 있다
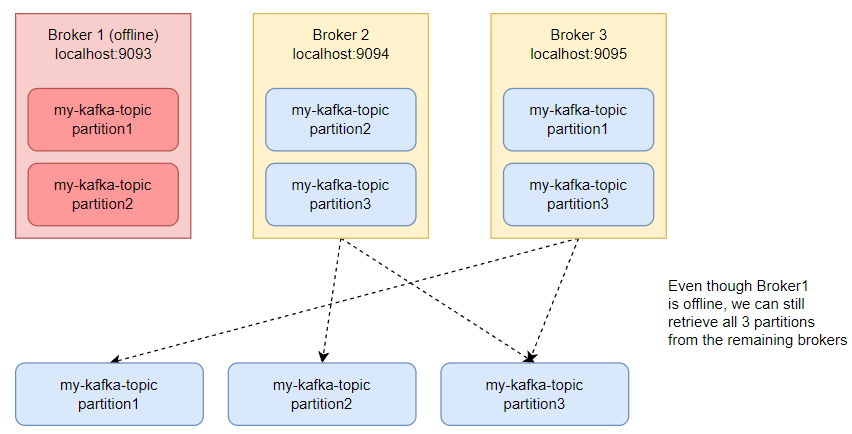
복제 테스트 : 브로커가 Offline 되면 어떤 일이?
이제 시스템에 Kafka 클러스터가 설정되었으므로 데이터 복제를 테스트해 보겠습니다.
실행한 3개의 브로커 중 첫 번째 브로커를 Control + C 키로 종료합니다.
# 첫번째 브로커 중지
[2022-01-01 02:09:13,095] INFO Metrics reporters closed (org.apache.kafka.common.metrics.Metrics)
[2022-01-01 02:09:13,097] INFO Broker and topic stats closed (kafka.server.BrokerTopicStats)
[2022-01-01 02:09:13,098] INFO App info kafka.server for 1 unregistered (org.apache.kafka.common.utils.AppInfoParser)
[2022-01-01 02:09:13,099] INFO [KafkaServer id=1] shut down completed (kafka.server.KafkaServer)
실행한 3개의 브로커 중 하나를 종료해도 클러스터가 클러스터가 제대로 실행되는지 아래 명령어를 실행합니다. 다른 터미널 창에서 다른 소비자를 시작해 보겠습니다.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9094 --topic my-kafka-topic --from-beginning --group group2
real-time data
두번째 입력
awesome!!!
first insert
여기에 추가한 것은 이 소비자를 다른 소비자와 구별하는 그룹 옵션입니다. 명령을 실행하면 처음부터 입력된 모든 메시지가 표시됩니다. 동일한 소비자인 경우에는 이미 데이터를 읽었기 때문에 데이터가 보지이 않습니다.
중개인 중 하나가 중지되었지만 데이터는 손실되지 않았습니다. 이는 이전에 설정한 복제 계수(replication-factor)를 2로 설정하여 데이터 사본이 여러 브로커에 존재하도록 했기 때문입니다.
? 의문점 : 위에서 보는 것처럼 입력한 순서대로 출력되지 않았습니다. 한글때문인지 아니면 원래 순서가 없는 것인지 정확한 이유는 파악하지 못했습니다. 추후 확인이 필요한 사안입니다.
다른 브로커를 중단하면 어떻게 될까요?
본 문서에서는 두번 째 브로커도 중지하고 테스트 해보겠습니다.
이 경우에는 데이터 조회가 되지 않네요? 브로커를 3개로 구성한 경우 2개의 브로커가 장애가 발생한 경우 정상 작동하지 않습니다. 즉, 브로커의 과반수 이상에 장애가 발생하면 정상 작동하지 않습니다.
Kafka 생산자 및 소비자 구현
클러스터를 실행하고 나면 애플리케이션 코드에서 생산자와 소비자를 구현할 수 있습니다. Golang 또는 Node.js에서 Kafka 생산자 및 소비자를 구현하는 방법은 링크된 문서를 참고하시면 됩니다.